Ghost Ownership: You Own the Capability, Not the Decision
This is the second deep dive in a series that started with an opening post called "Context Maps in the Age of AI." The through line, if you are joining here, is short. A Context Map was never really a map of systems. It was a map of coupling: between domain models, between teams, and between who gets to shape whose understanding. The claim of the series is that AI does not invalidate the context mapping patterns. It reveals which of them were load-bearing all along and which were only scaffolding, by changing the conditions they were quietly built on. The overview walked the whole catalog at survey depth and left the resolving to the posts that followed.
The first deep dive took the pair where AI changes the actor rather than the economics. It argued that a raw language model is, on the map, an upstream Big Ball of Mud, an upstream with no clean boundary of its own, and that every MCP server you stand up is an Open-Host Service you publish in front of it. It argued that a language model establishes no Published Language at its boundary, so if one is going to exist there, you have to bring it and hold the language model to it. And it ended on an example I chose precisely because it was the uncomfortable one: a language model returning not evidence about an applicant but the credit decision itself, a tier rather than a fact. When the thing crossing your boundary is evidence, your domain logic still owns the decision. When it is judgment, the decision has moved.
This post is about where it moves to. You can have a team that believes it owns its domain model. It has its own code, its own ubiquitous language, its own boundary drawn cleanly on the map. And a meaningful share of that domain model's decisions are quietly shaped by an upstream the team never consciously integrated with and cannot negotiate with. The map says the team is in control. The behaviour says otherwise, and nothing on the map shows the gap between the two.
I want to be honest about what this post is before you read further. It is the one in the series that carries what I think is its original contribution, the thing the title calls ghost ownership, and that makes it the one I am least sure of and most want pulled apart. Coining anything new in the DDD community is a high bar, and rightly so, because a weak addition pollutes the vocabulary everyone shares. So read what follows as a proposal offered for refinement, not a result I am declaring. I will commit to a definition later in the post, because vague gestures are not useful to argue with, but the commitment is an invitation to disagree with something specific, not a flag planted in the ground.
The capability is the bounded context
To get at that gap we have to be more careful about what the upstream actually is, and the most useful correction comes from Evans. Working through his own small AI integration, he made a point about naming that the last post leaned on and that this one turns into its starting move. The bounded context on the other side of your boundary is not "the LLM" in the abstract. It is a specific part of a specific system. In his case it was Claude Sonnet 3.5, with its particular behaviour and interface and quirks, a different context from GPT or Mistral or even a later Claude. Name the actual thing, not the category.
I want to push that one turn further, because in most real systems the actual thing is not even Claude Sonnet 3.5. What you integrate, run, and call yours is a composed capability. It is a language model version, yes, but wrapped in a prompt, a set of tool definitions, a retrieval corpus, a handful of policy rules, an output schema, an eval suite, some orchestration, and usually a human review step somewhere. That whole assembly is the bounded context. The language model sits inside it, behind the boundary, as the upstream Big Ball of Mud from the last post. The MCP server, where it has one, is the Open-Host Service on the front of it. Calling the bounded context "the LLM" is the same mistake as calling it "the abstract domain," just one level out. The honest name is the capability.
This is not a pedantic relabel. It changes what you think you own, and it is borne out by how these systems behave in practice. Through 2026 the working understanding across the field has settled on the idea that an AI feature's behaviour is set by the whole assembled context, the prompt and the retrieval and the schema and the evals, not by the language model alone. The clearest version of it I have seen described is a team whose feature went from broken to reliable without touching the language model at all, by adding eval discipline, bounding the retrieval, and routing requests more carefully. The language model never changed. The behaviour did.
Read that the generous way and it is good news. It means the capability really is the unit you own, the place where your design decisions live, and that you have far more control over its behaviour than "we are at the mercy of the provider" suggests. But read it the other way and the gap from the opening of this post comes into focus. If the behaviour of the capability can move that much without the language model changing, then it can also move without you deciding it should: through a prompt someone edited, a few-shot example someone swapped, a retrieval corpus that drifted, a routing default that changed under you. You own the assembly. You do not fully own what it decides. And that is the real question this post is circling. Not who owns the capability, which is you, but who owns the decisions made inside it.
Evidence, or judgment
Start with the distinction the last post ended on, because everything else hangs off it. A capability can return two very different kinds of thing across your boundary, and they sit in completely different places on the map even when the schema looks identical.
Take the credit risk capability from the Big Pug Loans example. It reads an applicant's submitted documents and responds. One version of it returns something like "documented missed payments in March and April, current debt-to-income ratio above the threshold the documents disclose." That is evidence. It is a set of observations about the applicant, expressed in facts your domain already knows how to weigh. Your Scoring context takes those facts, applies its own rules, and decides the tier. The decision stays inside the bounded context that owns it. The capability is a very good document reader and nothing more, which is exactly what a language model is good at.
The other version returns "ELEVATED." That is judgment. The tier is the decision, and the decision was made inside the capability, by the language model, against criteria nobody on your side wrote down or agreed to. The schema can be identical in both cases, a string and a rationale, validating cleanly, shipping, serving traffic. But the second one has moved a piece of your domain model across the boundary into an actor that establishes no language of its own, drifts without telling you, and cannot be asked to explain itself. The first one has not.
This is the hinge, so I want to be precise about it. Ghost ownership is not "you used a language model in your domain." It is the condition where a meaningful subset of your domain model's decisions are made by the language model inside a capability rather than by your team, while the map and the org chart and everyone's mental model continue to say the team owns them. The evidence version is not ghost ownership. The judgment version is. And the reason it is so easy to slide from one to the other is that the slide is invisible: it does not show up as a new dependency, a new call, or a new line on the map. It shows up only as a slightly different answer to the question of who decided, and that question is not one the map was ever built to ask.
It is a spectrum, not a switch, which is the next thing to get right. Between "returns a fact" and "returns the decision" there is a wide middle where the capability returns something that is mostly evidence but carries a thumb on the scale: a fact selected for relevance by criteria you did not set, an observation phrased in a way that pre-suggests a tier, a confidence score that quietly does the weighing for you. Most real capabilities live in that middle. So the useful question is not the binary "does the language model decide," it is "how far has the decision migrated," and that is a question with degrees. The degrees are what the next section is about.
The four ways it deepens
The migration happens in steps, and naming them matters because each step is a different relationship on the map and fails in a different way. I am borrowing the four levels of AI involvement from my post on Staffing and Procurement for Fast Flow, not to re-explain them, that post does that, but because they turn out to be the cleanest ladder for watching a decision leave a team's hands one rung at a time. The levels were originally about how deeply you delegate work to AI. Read against ownership, they become a description of how far your domain model has drifted out of your control.

How a decision leaves the team’s hands
At the first level, AI is a coding assistant. It completes lines, suggests implementations, accelerates the typing. Every meaningful decision is still made by a human who reads the suggestion and accepts or rejects it. At the architectural level the AI is invisible, and the bounded context is whatever it would have been without the tool. There is no ghost ownership here, or rather, there is none unless the team manufactures it by accepting suggestions it does not understand. The capability is not the issue at this level. The discipline of the people using it is.
At the second level, the work is spec-driven. A human writes a specification and the AI implements against it end to end. The macro model holds, because the spec is doing the job of a Published Language between you and the agent: it fixes the vocabulary and the shape of what gets built. But the spec does not fix everything, and the things it leaves unfixed get filled in from the language model's training distribution rather than your domain. The naming of the smaller concepts, the idioms, the way an edge case gets handled, the words that end up in the code for things the spec did not name. None of that is wrong, exactly. It is just not yours. You have entered a quiet Conformist relationship on everything the spec did not pin down, and the unsettling part is that you never decided to. You delegated a slice of your ubiquitous language without noticing you had delegated anything, because the spec felt like control and mostly was.
This is the failure mode worth dwelling on, because it is the one already visible in the wild and the one the rest of the community is starting to describe. The sharpest recent account of it, from the people who wrote the AWS piece on rediscovering DDD through MCP servers, puts it like this: AI coding agents are confident amplifiers of whatever vocabulary you hand them. Give an agent an imprecise term and it will not stop to ask what you meant, the way a human pair would. It will pick a plausible reading and implement it with total confidence, and the result compiles, passes the tests, and fails in production because the agent quietly fused two domain concepts that your business keeps apart. Their example is booking versus reservation. Their fix is the right one as far as it goes: write the ubiquitous language down precisely, name your tools deliberately, remove the ambiguity the agent would otherwise resolve for you.
I want to be generous about that fix and then say why it is not the whole story, because the gap between the two is most of what this post is for. Writing the language down is exactly the second-level move, and it works on the second-level problem: it controls the macro vocabulary so the agent stops guessing at the words you did care about. What it does not touch is the decisions you did not realize were decisions, and the drift that arrives later through the parts of the capability the spec never governed. A precise ubiquitous language is necessary. It is not sufficient, because precision in the words you wrote down says nothing about the judgments the language model is still making in the spaces between them. You can have a perfectly precise domain language and still be downstream of a language model that is shaping a subset of your decisions, which is the thing the "be precise" cure cannot reach.
At the third level, the language model is in the room while you model. It is a thinking partner in design, questioning assumptions, proposing structures, suggesting what to call things. This is the level I am most wary of, because it is where the ubiquitous language itself starts to drift toward what the language model would call it rather than what your domain calls it. The cohesion of a bounded context, as I have argued elsewhere, lives in its language: the words are the cohesive forces that hold the model together, and when you find several vocabularies competing inside one context, cohesion is already eroding. A language model in the modeling loop is a steady, fluent, plausible source of a second vocabulary, and it never gets tired of offering it. Used with discipline it sharpens your thinking. Used without, it quietly re-words your domain until the language on the whiteboard is half yours and half the language model's, and no one can point to the moment it happened.
At the fourth level, the AI runs the full lifecycle, from analysis through to tested code, with a human setting direction and reviewing outcomes. This is where the bounded context starts to resemble a Big Ball of Mud, but for a reason Vernon's definition did not anticipate. The classic Big Ball of Mud is internally inconsistent: models mixed, boundaries blurred, the mess visible if you look. A fourth-level capability can be locally clean, each file sensible, each function coherent, and still have no conceptual integrity at the level of the whole, because no human has ever held the whole model in their head. How far this goes depends entirely on the review. A team that reviews deeply, that reconstructs the conception and makes it its own, can still own the model at this level, and some do. But review at full-lifecycle speed tends to check whether each piece works, not whether the whole hangs together as one idea, and when it slips that way the mud is not in any one place. It is in the absence of a single mind that owns the conception. That is a new way for a context to be a Big Ball of Mud: not too many cooks, but, when the review thins out, no cook at all. That idea deserves its own treatment and is more aside than argument here. For this post it is enough that the fourth level is where ghost ownership stops being about a subset of decisions and becomes about the whole domain model.
What ghost ownership is, and is not
A definition is what lets you argue with me, so here is the one I want to put on the table.
Ghost ownership is a relationship in which a team believes it owns a domain model, but a meaningful subset of that model's decisions are determined by an upstream actor, the language model inside a capability or the training distribution behind it, that the team never consciously integrated with and cannot negotiate with. The upstream is invisible at design time. It shows up only later, and only indirectly, as a slow drift of the model's decisions away from the language and the rules the team thinks it is enforcing.
The phenomenon shows up wherever AI is involved at a depth that shapes a team's domain model or its decisions, whether that depth arrives through a runtime capability deciding things or through the modeling work itself. But it concentrates, and does the most damage, where a team is leaning heavily on AI in the domain modeling, because that is where the language model is closest to the thing a team is supposed to own most completely: the words and concepts the model is made of. The two teams I will describe later, drifting because a capability decided for them, are one face of it. A team modeling hand in hand with a language model until it can no longer tell which concepts were its own is the other, and the sharper one.
It is worth naming the two faces, because you find and defend them differently. Decision ghost ownership is the runtime case, where the capability decides inside the running system, and you catch it by looking at outputs, evals, and whether a business rule lives in your code or in the language model. Language ghost ownership is the design-time case, where the language model shapes the concepts while you model, and you catch it by looking at vocabulary and concept provenance, at whether the terms still trace back to your domain experts. Same loss of ownership, two different places to look for it.
The reason I think this needs a name, rather than being filed under something we already have, is that it does not behave like any of the patterns it superficially resembles, and the differences are the whole point.
It is not a Conformist. A Conformist relationship is explicit and known. You can see the upstream, you have decided to adhere to its model wholesale, and you made that decision on purpose to save the cost of translation. Everyone on the team could tell you they are conforming, even if they regret it. Ghost ownership is the opposite on the one axis that matters: the team does not know it is happening. There is no decision to point to, no moment where anyone chose to adopt an upstream model, because the upstream was never visible as a party to integrate with in the first place. A Conformist has conformed. A team in ghost ownership believes it is still in charge.
It is not a Shared Kernel. A Shared Kernel is the tightest, most deliberate coupling on the map: two teams agree to share a part of the model as a tangible artifact, a library or a schema, with binary compatibility and an explicit agreement not to change it without consultation. Every word of that is conscious and bilateral. Ghost ownership shares nothing deliberately and agrees to nothing. If anything it is the photographic negative of a Shared Kernel: a kernel you are sharing with an upstream, shaping your model, that you never agreed to and cannot see.
It is not a Partnership. Partnership is the mutually dependent case, two contexts that succeed or fail together and coordinate closely to do it, and coordination assumes a partner who can be reasoned with. The defining feature of the ghost upstream is that it cannot be a party to anything. It cannot negotiate, cannot commit, cannot be scheduled, cannot be asked to preserve a concept in its next version. Partnership without a partner who can answer is not a weak Partnership. It is a different thing that needs a different name.
So what kind of thing is it. I do not think ghost ownership is a single pattern sitting alongside the nine in the catalog. I think it is closer to a family of behaviours at the human and agent boundary, and I want to be clear that proposing a family rather than a pattern is a deliberate choice with precedent in my own work. In DDD by Example I argued that the Customer/Supplier relationship, when you find it degraded in a real landscape, is better described by naming the behaviour you actually see: an Over-Cautious Supplier who ships rarely out of fear, a Reluctant Supplier who builds a wall of process, a Vetoing Customer who blocks the upstream. Those are not new patterns competing with Customer/Supplier. They are names for how the relationship behaves when it goes wrong, and they earn their place because they are useful when you are analyzing an existing system and trying to say what is actually happening. Ghost ownership is the same kind of addition for the same kind of reason. It is a name for a behaviour you find in the wild, most useful when you are looking at a landscape that includes AI capabilities and trying to say honestly who owns what.
The real argument for naming it is honesty about what the map asserts. A context map is a claim about who affects whom. If a meaningful share of a team's decisions are being made by an upstream the map does not show, then the map is not merely incomplete, it is asserting something false: that the team is in control. A name for the gap is what lets you draw the truer map, the one that admits the team is not as in charge as the boxes suggest.
If you want to know whether you have it, the questions that surface it are simple. Can the team state the decision rule without pointing at the language model? Does the capability return evidence, or does it return judgment? Do the terms in the domain model still trace back to your domain experts, or did some of them arrive from the language model? Do two contexts you call Free drift together after a shared version changes? And when someone edits a prompt or swaps a retrieval corpus, does a domain decision move without anyone treating it as a change worth reviewing? None of these is a test that returns a verdict. They are smells, and like all smells they tell you where to look, not what you will find. But when the honest answer to several of them is the uncomfortable one, you are probably looking at ghost ownership.
I will say plainly that I am not certain the name is right, and the name is the part I hold most loosely. I have reached for "ghost" because it captures the two things at once: the upstream is invisible, and the ownership is a ghost of itself, present in name and absent in fact. I considered "Phantom Upstream," which leans harder on the upstream/downstream vocabulary we already have, and "Implicit Conformist," which is accurate for one of the failure modes but too narrow for the whole family. If the community lands on a better word I will use it gladly. What I am more confident about than the name is that the phenomenon is real, that it is not any of the three patterns it resembles, and that our maps are currently lying about it. The label is negotiable. The gap is not.
Apparent freedom
A while ago I sat with two teams at the same company who had, by every measure they knew to check, nothing to do with each other.
They were a textbook case of Separate Ways. Different parts of the product, different codebases, no shared database, no shared library, no API between them, no standing meeting, no reason to coordinate. If you had drawn their stretch of the context map you would have drawn two boxes and deliberately left the space between them empty, and you would have been right to, by the rules we had. Both teams were happy. Independence is comfortable, and they had earned theirs.
Then both of their products started getting subtly worse in the same way at the same time, and neither team could explain it. One was summarizing customer interactions for a support workflow. The other was extracting structured details from incoming documents for a separate workflow entirely. Over a few weeks the support summaries started flattening certain distinctions the team had relied on, and the document extraction started mislabeling a category it had handled fine for months. Two unrelated regressions in two unrelated contexts. Except they were not unrelated. Both capabilities called the same language model, through the same internal gateway, and the provider had rolled the version behind that gateway. Neither team had touched the language model. Neither team had been told it changed. And because the map said they were Separate Ways, neither team thought to ask the other a single question, because on the map there was no other to ask.
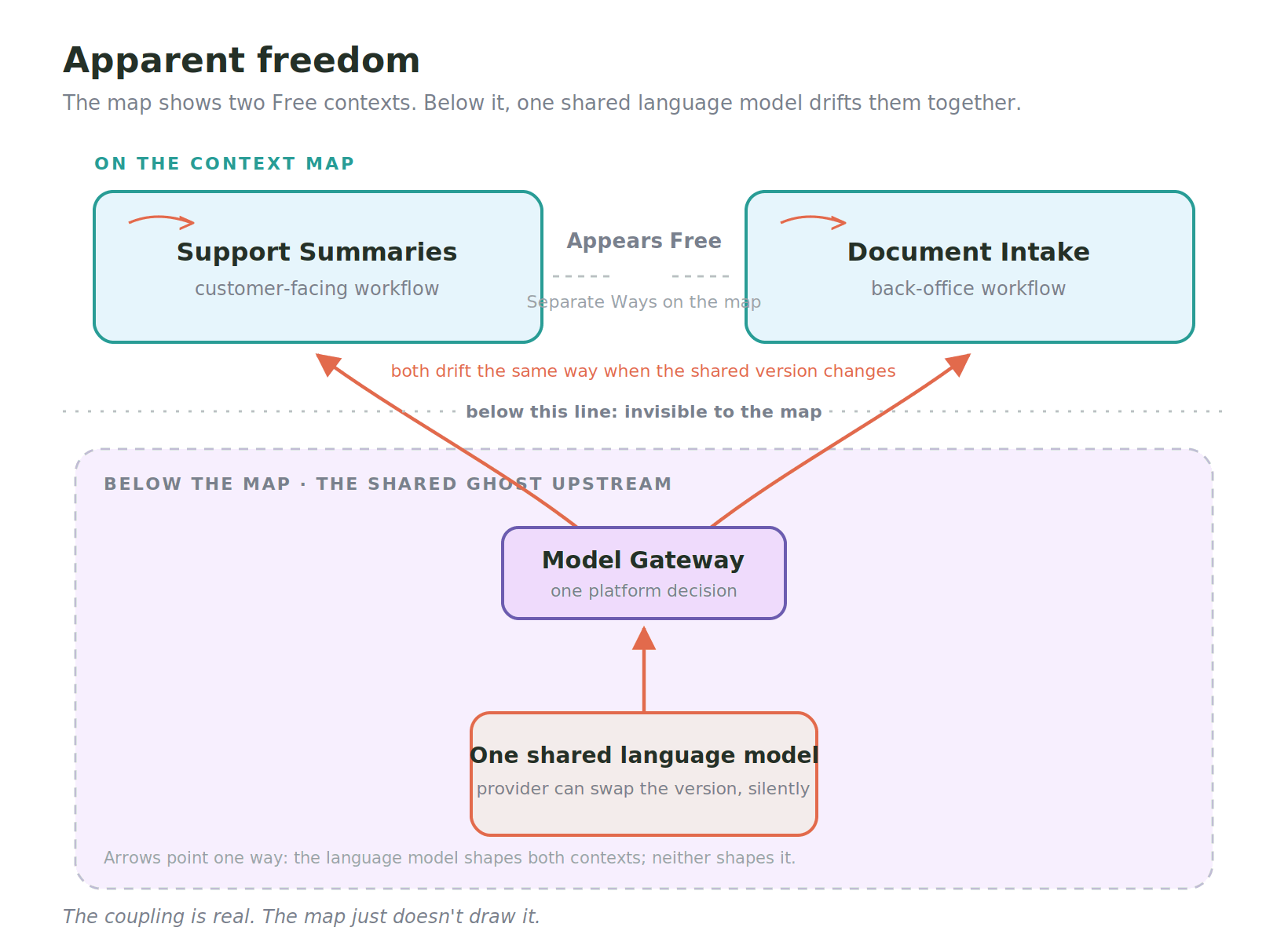
Apparent Freedom
That is the failure I want to name as the most vivid form of ghost ownership, and it forces a distinction inside the idea of Free. The book's definition of Free is clean: a context is Free when changes in other contexts do not affect its success or failure, with no organizational or technical link of any kind. Those two teams satisfied that definition completely at the level the map can see. There was no link of any kind that anyone had documented, because there was no link of any kind that anyone had made. And yet a change in one place produced correlated change in both, which is exactly what Free is supposed to rule out. So there are two different states wearing the same word. There is classical Free, no link of any kind. And there is what I would call apparent freedom: no documented link, no link anyone made on purpose, and underneath it a shared ghost upstream producing correlated drift. On the map they look identical. In the world they could not be more different.
It is worth being clear about how this sits next to the rest of the post. Ghost ownership, until now, has been a failure inside a single context: a team that does not fully own the decisions in its own model. Apparent freedom is the same root cause seen from the outside, between two contexts: a mapping failure, where two boundaries that share one ghost upstream look independent and are not. One is about what happens inside a box. The other is about a line the map does not draw between two boxes.
The mechanism is not exotic, and it is worth being clear that it is real rather than a thought experiment. Two systems that depend on the same language model are not independent just because no wire runs between them, because the thing they share is not a wire, it is a source of decisions. When that source moves, both move, in the same direction, at the same time, for the same reason. The machine learning research community has started measuring a version of this directly under the name behavioural entanglement: nominally independent language models that share training lineage exhibit synchronized failures and correlated behaviour, so that apparent agreement between them reflects shared origin rather than independent confirmation. That is the model-to-model version of the same shape, and I am borrowing it only as evidence the underlying mechanism is real, not as the claim itself. The version on your context map is sociotechnical: two teams, not two models, drifting together because they drink from the same well and the map does not draw the well.
Notice where the shared upstream came from in that story. Neither team chose a language model; a platform team chose one for everybody and put it behind the gateway, which is how most organizations will actually arrive at this. That turns the choice of language model into a central platform decision, and it means a single team that most people would never think to draw as a domain actor is quietly introducing ghost ownership into every context downstream of the gateway at once, including contexts that are Separate Ways from each other. When that team swaps the language model, a dozen unrelated contexts drift together, and none of them have that team on their map, because procuring a model never felt like taking on an upstream. There is a whole post in what that does to the platform team's place on the map, and this is not it, but the gateway is the most common machine by which apparent freedom gets manufactured at scale.
Here is the part I find genuinely uncomfortable, because it pulls in two directions at once. The opening post argued that AI makes Separate Ways more attractive, and it does: the old objection to Separate Ways was the cost of building a second specialized solution instead of integrating with an existing one, and AI has driven that cost down sharply, so going your own way is cheaper than it has ever been. But AI simultaneously makes the freedom that Separate Ways is supposed to deliver harder to actually achieve, because the cheap second solution you build will very likely reach for the same language model the first one did. You have made the deliberate choice to be independent, and you have quietly undermined it in the same motion. You swapped a visible coupling, the integration you chose not to build, for an invisible one, the shared upstream you never noticed you had both adopted. The map shows the coupling you removed. It does not show the one you took on.
I want to hold the line on precision here, because the strong version of this claim is easy to overstate into a false one. I am not saying every Free relationship is now secretly coupled. Two contexts that depend on different language models, or that use AI only as a coding assistant where the model never touches their domain decisions, can be genuinely, classically Free, and most relationships on most maps still are. The narrow claim is the only one I will defend: when two contexts depend on the same language model at a depth that shapes their decisions or their language, they are not Free, they are apparently Free, and the difference is invisible until both drift at once. The practical consequence is small to state and large to act on. Choosing Separate Ways no longer buys you independence by itself. If real independence is what you are after, it now has a price the map should show: deliberate diversity in which language model each context depends on, or, at the least, an honest mark on the map admitting that the independence is conditional on a shared upstream nobody is watching.
How much ghost ownership you can afford
So far this is a named risk and nothing to do about it, which is not worth much. Here is what I think you can do, offered like the rest as a proposal.
The amount of ghost ownership a bounded context can tolerate is not fixed. It depends on what the context is for. And the lens that tells you what a context is for is one the DDD community already has: the strategic classification of its subdomain into Core, Supporting, or Generic.
Stated as a single heuristic: ghost ownership is acceptable in a Generic subdomain, tolerable in a Supporting one, and dangerous in a Core one.

How much ghost ownership you can afford
The logic is almost mechanical once you say it. A Core subdomain is where you differentiate, the reason customers choose you, the part of the model that is supposed to be more yours than anyone else's. It is precisely the place where having a meaningful subset of your decisions quietly made by the same language model your competitors are calling is most corrosive, because the thing that is supposed to set you apart is being shaped by an upstream that does not know your business and is shared with the field. Ghost ownership in a Core domain is differentiation leaking out through a boundary nobody is watching. A Supporting subdomain has to work but is not where you win, so a degree of ghost ownership is a cost you can carry as long as you know you are carrying it. And a Generic subdomain is one where you were never going to differentiate anyway, where the whole point is to consume a commodity capability and move on. Ghost ownership in a Generic domain is not a problem. It is the entire reason you reached for AI there in the first place.
One caution keeps the heuristic honest. Generic is a statement about differentiation, not about risk. A subdomain can be Generic in the strategic sense, the place you were never going to win, and still be one you cannot afford to ghost-own casually, because regulation, safety, legal exposure, or brand trust raise the cost of a wrong decision regardless of where your differentiation lives. Identity verification, fraud screening, and compliance classification are the usual examples: commodity capabilities by the strategic test, and dangerous places to let an unowned upstream decide. So read the heuristic as governing strategic tolerance, with operational risk as a second constraint that can pull ownership tighter than the subdomain type alone would suggest.
I want to place this carefully next to something I have argued before, because the two are easy to confuse and they are not the same. In my post on staffing and procurement I argued that the Cynefin classification of a domain sets a ceiling on how deeply you can delegate work to AI: a Complex domain, where cause and effect only resolve in hindsight, cannot be handed to AI past a shallow level, because you cannot specify what you do not yet understand. That ceiling is about the nature of the problem. The heuristic here is about something else: the strategic value of the domain whose decisions are at stake. Cynefin tells you how much you can delegate before the work fails. The DDD classification tells you how much ghost ownership you can absorb before your differentiation erodes. They are two different ceilings answering two different questions, and a context sits under both at once.
Most of the time they agree, which is why it has been easy not to separate them. Core domains tend to be Complex, so the problem nature and the strategic value point the same way and both ceilings come down together. The reason it is worth pulling them apart is the cases where they diverge, because that is where having the second lens earns its keep. The sharpest one is a Core domain that happens to be Clear: a differentiating capability whose problem is well understood, with a known good solution. It is a rare and often temporary state, since a Core domain with a known good solution is usually one drifting toward Supporting, which is part of why the old lens overlooked it. But while it lasts, Cynefin alone would say go ahead and delegate deeply, the problem is specifiable. The ghost ownership lens says stop, because no matter how clear the problem is, this is where you differentiate, and handing your differentiation to a shared upstream is a strategic mistake even when it is a technically safe one. The old lens sees a green light. The new lens sees the thing the old lens was never looking for.
There is a structural payoff to the classification that ties the whole post together. If ghost ownership is acceptable in Generic and dangerous in Core, then the job of the boundary between them is to stop the contamination from spreading. This is what an Anticorruption Layer is for, read in a slightly new light: not only translating an upstream model into your own, but keeping the ghost upstream that you have happily accepted in a Generic capability from seeping into the Core domain next door, where you have decided you cannot afford it. The Anticorruption Layer becomes the firewall between the part of your system where you let the language model decide and the part where you must not. Which capability is allowed to be ghost-owned, and where the firewall around it has to stand, is a design decision the classification hands you directly.
This is also where I want to mark a difference from the nearest existing treatment, because someone will rightly ask how this relates to it. Philipp Kostyra, in his work on agents as bounded contexts, maps the use of a language model to subdomain type: a language model as a Generic utility for summarization or filtering, and so on. That is a useful mapping and I am not arguing with it. The heuristic here maps something different, not the use but the tolerance: how much loss of ownership a subdomain can survive. The two fit together. His tells you what kind of work to give the language model in each subdomain. Mine tells you how much of your own decision-making you can afford to lose there. You want both answers, and they are not the same answer.
What this is, and what I am asking
Let me be clear about the size of the claim, because the temptation in a post like this is to round it up, and rounding it up would be the way to get it wrong.
I have not described a finished pattern. I have described a behaviour I keep seeing, given it a definition precise enough to disagree with, separated it from the patterns it is not, and proposed a single heuristic for what to do about it. That is the most I think the evidence currently supports, and possibly slightly more. The name may not survive contact with the community, and I would rather it be replaced by a better one than carried past its usefulness. The boundaries between ghost ownership and an ordinary undiscovered Conformist are fuzzier than a clean post would admit. And the Core, Supporting, Generic heuristic is a starting point for a conversation about where to put your firewalls, not a rule you can apply without judgment.
What I am confident about is smaller and, I think, solid. A team can own a capability and not own the decisions inside it. That gap does not show up on a context map drawn the way we draw them today. It deepens as AI moves from assisting the typing to shaping the language to running the lifecycle, and it concentrates exactly where you can least afford it, in the domains that are supposed to be most your own. Two contexts that look Free can be drifting together because they share an upstream the map does not draw, and in a lot of organizations that upstream is a single platform decision sitting behind a gateway. None of that depends on the word "ghost" being the right word.
So this is the post in the series I most want argued with. If you have a team that is living some version of this, or a cleaner way to carve the definition, or a reason the whole framing is wrong, that is the conversation I am trying to start. The contribution is not the name. The contribution is the claim that our maps have a blind spot precisely where AI now sits, and that we will need to learn to draw the thing in the blind spot before we can manage it. How to actually draw it, the notation for a ghost upstream and a mark for apparent freedom on a real map, is the next thing I want to work out, and it is where this series goes next.
What comes next
This post named a relationship and left several things undone, and each of them is a post.
The most immediate is the one the close just pointed at: how to actually draw any of this. A ghost upstream that the current notation has no shape for, a mark that separates apparent freedom from the real thing, the Big Pug Loans map redrawn for a system that now has a language model deciding inside one of its contexts. Naming the gap is only useful if you can put it on the map, and the map needs new vocabulary before you can. That is the next thing I want to work out, and I would like to do it in the open, with templates anyone can take and argue with.
Closer to the practical question most readers will have is the one I deliberately did not answer here. I drew the line between a capability you let decide and a domain you must protect, and I said an Anticorruption Layer is the firewall between them, but I gave you no criteria for where to put it. When do you conform to the language model on purpose, when do you wrap it, when do you keep the decision in deterministic code and refuse the model entirely? That is the most actionable post in the series, and it is about being downstream of a model no team owns, where the Conformist breaks softly instead of loudly and the provider turns out to be the most reluctant supplier you have ever had.
And underneath the apparent-freedom story is the platform team I kept gesturing at and would not draw. Once the shared upstream is a single decision behind a gateway, the team that made that decision is sitting between every other team and the model providers, shaping all of them and appearing on none of their maps. What that team is, in context-mapping terms, and what influence flow even means when the most influential actor on the map is one nobody put there, is a question large enough to need its own treatment. It is also where the series stops being only about boundaries and starts being about how the whole organization is shaped by what it cannot see.
If one of these is the one you most want next, tell me. I read what comes back from a post before I commit to the order of the next, and this is the post whose responses I most want to read.
References
Related writing
Eric Evans. Context Mapping with an AI-based Component. Domain Language, January 2026. https://www.domainlanguage.com/articles/context-mapping-an-ai-based-component/ The precise-naming point this post opens by extending: a bounded context is a specific part of a specific system, Claude Sonnet 3.5 rather than "the LLM." I push it one turn further, from the language model version to the composed capability.
Vaughn Vernon. Implementing Domain-Driven Design. Addison-Wesley, 2013. The Big Ball of Mud definition the fourth-level argument reinterprets, and the canonical catalog phrasings the series builds on.
Michael Plöd. Hands-on Domain-driven Design by Example. The catalog, the three flows, the three team dependencies, the definition of Free, the Shared Kernel as binary compatibility, and the downstream anti-pattern family (Over-Cautious Supplier, Reluctant Supplier, Vetoing Customer) that ghost ownership is modeled on as a behaviour-describing addition for analyzing existing landscapes. The Big Pug Loans case study is from here too.
Michael Plöd. Staffing and Procurement for Fast Flow.https://www.michael-ploed.com/blog/staffing-and-procurement-for-fast-flow The four levels of AI involvement this post rereads as a gradient of ownership loss, and the Cynefin ceiling on delegation depth that the Core, Supporting, Generic heuristic sits beside.
Michael Plöd. Bounded Contexts Are All About Cohesion.https://www.michael-ploed.com/blog/bounded-contexts-are-all-about-cohesion The argument that a bounded context's cohesion lives in its language, which the third-level case draws on directly.
Michael Plöd. Context Maps in the Age of AI.https://www.michael-ploed.com/blog/staffing-and-procurement-for-fast-flow The opening post in this series. The three flows, the load-bearing and scaffolding distinction, and the foreshadowing of ghost ownership and apparent freedom this post develops.
Michael Plöd. MCP as Open-Host Service, and the Published Language the LLM Cannot Give You.https://www.michael-ploed.com/blog/the-published-language-an-llm-cannot-give-you The first deep dive. The language model as an upstream Big Ball of Mud, the Published Language imposed at the boundary, the Big Pug Loans credit-risk example, and the evidence-versus-judgment distinction this post starts from.
AWS. Rediscovering Domain-Driven Design, one MCP server at a time, and its follow-up on vocabulary ambiguity, Your agent keeps using that word.https://dev.to/aws/rediscovering-domain-driven-design-one-mcp-server-at-a-time-1i79 The confident-amplifier reading of AI coding agents: hand an agent an imprecise term and it implements a plausible reading without asking, so the code compiles and passes tests and still fuses two domain concepts the business keeps apart. The closest living account of the silent-conformism failure mode, with a fix, a precise ubiquitous language, that I argue is necessary but not sufficient.
Philipp Kostyra. Agent as Bounded Context, Parts 1 and 2. Medium. Part 1 and Part 2. Maps the use of a language model to subdomain type. The Core, Supporting, Generic heuristic here maps something different, the tolerance for ghost ownership, and the two fit together rather than compete.
Research on behavioural entanglement among large language models, for example the statistical auditing work on how independent large language models actually are. Used here only as evidence that nominally independent models sharing training lineage show synchronized failures and correlated behaviour, the model-to-model version of the correlated drift this post describes between teams.